Alpamayo-R1是英伟达研发的具有推理能力的视觉-语言-行动(VLA)模型,专为提升自动驾驶在复杂场景中的决策能力设计。通过引入因果链推理机制,让车辆能像人类驾驶员一样分析场景因果关系(如“因前方有行人需减速”),而非单纯执行预设指令。模型采用多摄像头输入和轻量级编码技术降低计算成本,并通过强化学习优化轨迹规划,实测在长尾场景中使事故风险降低35%。创新点包括结构化因果标注数据集和模块化设计,支持实时推理延迟低于100毫秒。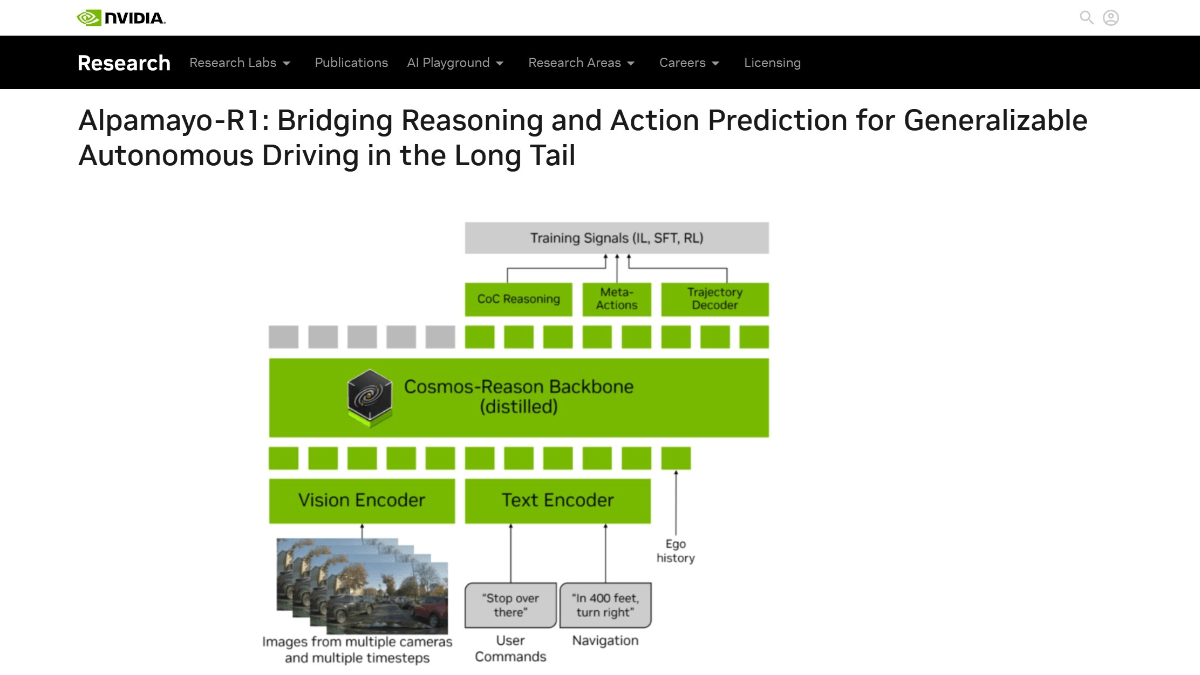
>>展开阅读
Ovis-Image 是阿里巴巴国际数字商务集团 AIDC-AI 团队开源的 70 亿参数文生图模型,专注于高质量文本渲染。基于 Ovis-U1 架构,继承了先进的视觉解码器和双向 Token 精炼器,能处理复杂的文本布局需求,如海报、横幅、LOGO 等。Ovis-Image 在文本渲染方面表现出色,支持多种字体、尺寸和长宽比,同时保持清晰可辨的文本和语义连贯性。
>>展开阅读
悟界·Emu3.5是北京智源人工智能研究院开源的多模态世界大模型,参数量达340亿,具备原生世界建模能力。通过10万亿多模态Token(含790年视频数据)训练,能模拟物理规律,实现图文生成、视觉指导、世界探索等任务。创新的"离散扩散自适应"技术使其图像生成速度提升20倍,性能超越Nano Banana模型。模型已开源,适用于具身智能、虚拟场景构建等领域。
>>展开阅读
阿里巴巴通义实验室开源 Z-Image AI 绘画模型,其中 Z-Image-Turbo 在仅需 8 次函数评估的情况下,可达到或超过领先模型的性能。分享一个免费在线免费使用「Z-Image Turbo」网站,据介绍性能和效果碾压 Flux。免费在线体验,支持提示词示例与任务追踪。
>>展开阅读
刚刚,Transformers v5 发布首个 RC(候选) 版本 v5.0.0rc0。
>>展开阅读
一款采用 Go + Vue3 + element-plus 实现的 AI 大语言模型开源解决方案「GeekAI」集成了 GPT、Azure、ChatGLM、讯飞星火、文心一言等多个平台的大语言模型。AI 助手全套开源解决方案,自带运营管理后台,开箱即用。
>>展开阅读
GELab-Zero是阶跃团队开源的端侧多模态GUI Agent模型,基于Qwen3-VL-4B-Instruct基座模型构建,参数量为4B。能识别UI元素并执行点击、滑动等操作,支持跨应用任务处理(如外卖、出行等场景),具备零样本适应能力,可适配未见过的App。模型采用Apache 2.0协议开源,支持Ollama快速启动,自动处理ADB连接和依赖安装,提供任务录制回放功能。在AndroidDaily基准测试中,准确率达73.4%,性能超越同尺寸主流模型,优于参数量更大的GUI-Owl-32B。
>>展开阅读
Depth Anything 3(DA3)是字节跳动Seed团队研发开源的3D视觉重建模型。通过单一Transformer架构实现任意视角下的空间几何重建,仅需预测深度图和射线图即可还原三维场景,相比传统方法精度提升35.7%,运行效率达126 FPS。其创新点在于采用"深度-射线"统一表征法,无需多任务模块,支持从单张图片到多视角视频的灵活处理,能适配自动驾驶、SLAM等场景。模型在视觉几何基准测试中全面超越现有方法,相关代码和演示已公开。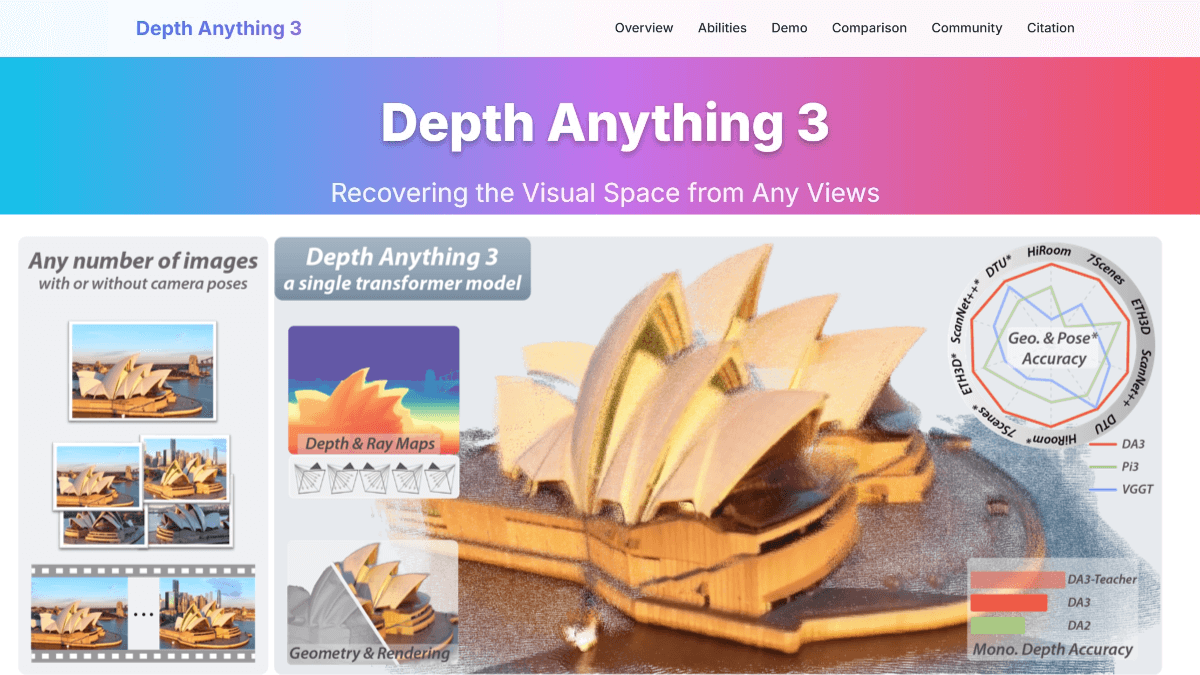
>>展开阅读
- 1
- 2
- 3
- 4
- ...
- 121
- »