Supertonic - 开源的高性能AI 文本转语音系统,极速离线运行
Supertonic是开源的高性能的文本转语音(TTS)系统,专注于在本地设备上快速生成语音。采用ONNX Runtime技术,可在手机、电脑甚至树莓派等设备上运行,支持23种语言和语音克隆,无需网络连接即可实现毫秒级响应。特色在于处理复杂文本的能力,能自然朗读包含数字、符号的非标准文本,适合开发实时语音应用。用户可通过GitHub获取开源代码和模型,支持Python、Node.js等多种编程环境。
Supertonic是开源的高性能的文本转语音(TTS)系统,专注于在本地设备上快速生成语音。采用ONNX Runtime技术,可在手机、电脑甚至树莓派等设备上运行,支持23种语言和语音克隆,无需网络连接即可实现毫秒级响应。特色在于处理复杂文本的能力,能自然朗读包含数字、符号的非标准文本,适合开发实时语音应用。用户可通过GitHub获取开源代码和模型,支持Python、Node.js等多种编程环境。
最近不少消费者发现,原本亲民的固态硬盘价格已悄然翻倍。据报道本轮涨价的核心驱动力来自 AI 算力需求的爆发,AI 服务器在推理阶段需处理 TB 级资料,仅靠 DRAM 或 HBM 无法承载,因此高容量 HDD 与 SSD 也同步出现供应吃紧。面对存储价格的高涨,当下价格过高,现在入手不划算,如果没有必须购买的情况,可以选择将网盘作为一种 “本地磁盘” 的替代方案,可低成本实现存储需求的过渡。那么如何把网盘挂载到你的电脑里,就像用自己的本地硬盘一样那么方便?这里给大家推荐这款「SUG Drive」工具,据介绍是基于 AList 挂载,所以基本上支持主流的网盘,包括:123云盘、百度网盘、115网盘、夸克网盘、阿里云盘、天翼网盘等。

MiMo-Embodied是小米集团开源的全球首个成功融合具身智能(Embodied AI)与自动驾驶的跨具身基础模型。解决具身智能与自动驾驶之间的知识迁移难题,实现两大领域的任务统一建模。同步支持具身智能的三大核心任务(可供性推理、任务规划、空间理解)与自动驾驶的三大关键任务(环境感知、状态预测、驾驶规划),形成全场景智能支撑。通过统一架构整合室内操作(如机器人导航、物体交互)与户外驾驶(如环境感知、路径规划)任务,打破传统视觉语言模型(VLMs)局限于单一领域的局限。
AgentEvolver是阿里巴巴通义实验室开源的智能体进化系统。通过自我提问、自我导航和自我归因三种机制,实现智能体的自主学习与进化。AgentEvolver采用服务导向架构,将环境沙盒、LLM和经验管理模块化,支持多种外部环境和工具API的无缝集成。其优势在于高效学习、成本效益和持续进化能力。与传统强化学习方法相比,AgentEvolver在探索效率、样本利用率和适应速度上表现出色,减少了人工数据集的依赖和随机探索成本。AgentEvolver的框架代码已开源,为开发者提供了灵活的定制和开发空间。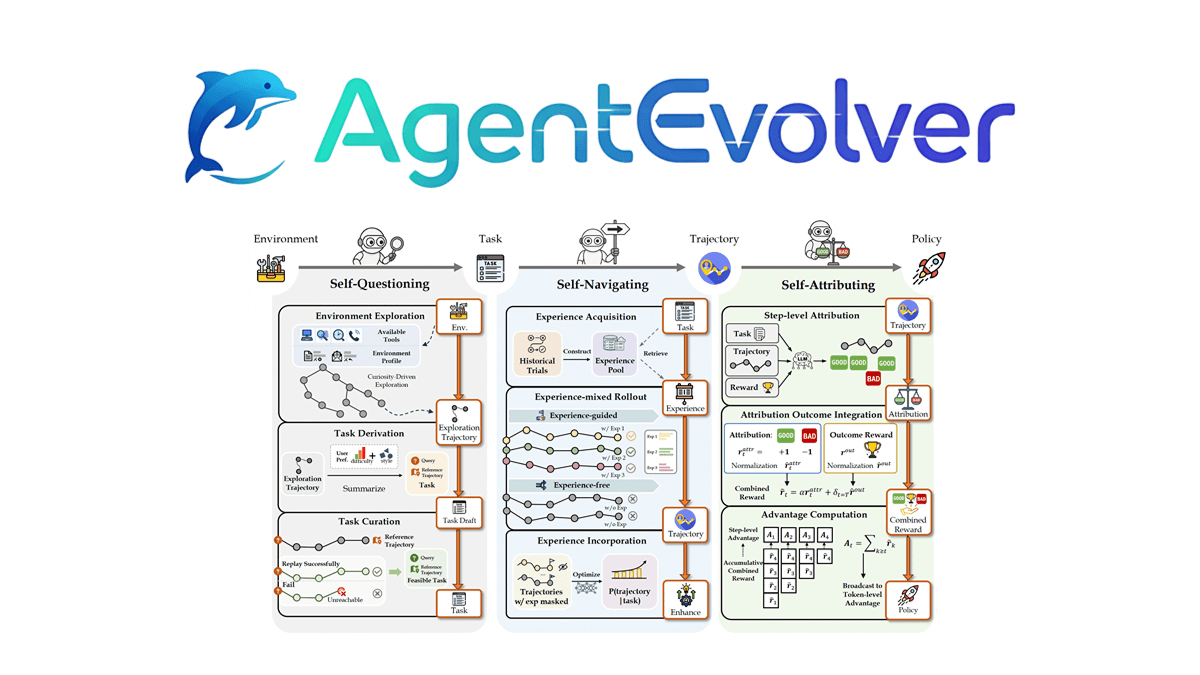
SAM 3D是Meta公司推出的基于SAM系列的3D重建模型,包含SAM 3D Objects和SAM 3D Body两个分支。其中SAM 3D Objects能从单张照片生成可交互的3D物体模型,支持复杂场景和遮挡处理;SAM 3D Body专注于人体重建,可精准还原姿势、形状及关键点,适用于虚拟人和动画制作。模型采用统一架构整合2D分割、深度预测等任务,通过创新数据引擎大幅提升了真实场景的泛化能力,相关代码和体验平台已开放。
Parallax是分布式AI实验室Gradient开源的全球首个“全自主AI操作系统”。支持在Mac、Windows等异构设备上跨平台部署大模型,让用户完全掌控模型、数据与AI记忆。系统内置网络感知分片与动态任务路由机制,可根据推理负载实现智能调度,在单机、本地多设备、广域集群三种模式间无缝切换。Parallax已兼容Qwen3、Kimi K2、DeepSeek R1、gpt-oss等40余种开源大模型。
HunyuanVideo 1.5 是腾讯混元大模型团队开源的轻量级视频生成模型,基于 Diffusion Transformer(DiT)架构,参数量为 8.3B。支持生成 5-10 秒的高清视频,分辨率可达 480p 和 720p,可通过超分模型提升至 1080p。用户可通过输入文字描述(文生视频)或上传图片配合文字描述(图生视频)来生成视频。模型支持中英文输入,具备强指令理解与遵循能力,能实现多样化场景,如运镜、流畅运动、写实人物等。支持写实、动画、积木等多种风格,可在视频中生成中英文文字。HunyuanVideo 1.5 的创新 SSTA 稀疏注意力机制显著提升了推理效率,可在 14G 显存的消费级显卡上流畅运行。