HunyuanVideo 1.5 是腾讯混元大模型团队开源的轻量级视频生成模型,基于 Diffusion Transformer(DiT)架构,参数量为 8.3B。支持生成 5-10 秒的高清视频,分辨率可达 480p 和 720p,可通过超分模型提升至 1080p。用户可通过输入文字描述(文生视频)或上传图片配合文字描述(图生视频)来生成视频。模型支持中英文输入,具备强指令理解与遵循能力,能实现多样化场景,如运镜、流畅运动、写实人物等。支持写实、动画、积木等多种风格,可在视频中生成中英文文字。HunyuanVideo 1.5 的创新 SSTA 稀疏注意力机制显著提升了推理效率,可在 14G 显存的消费级显卡上流畅运行。
>>展开阅读
LongCat-Video是美团LongCat团队开源的13.6亿参数视频生成模型,采用MIT开源协议,支持文生视频、图生视频和视频续写三大任务。模型通过"粗到细"生成策略和块稀疏注意力机制,能在数分钟内生成720P高清长视频,保持色彩一致性且无质量衰减。技术亮点包括多奖励强化学习优化,性能接近商业级SOTA模型,在内部测试中多项指标超越同类开源模型。模型已在Hugging Face和GitHub开源,提供文本/图像输入、视频续写等一键式部署方案。
>>展开阅读
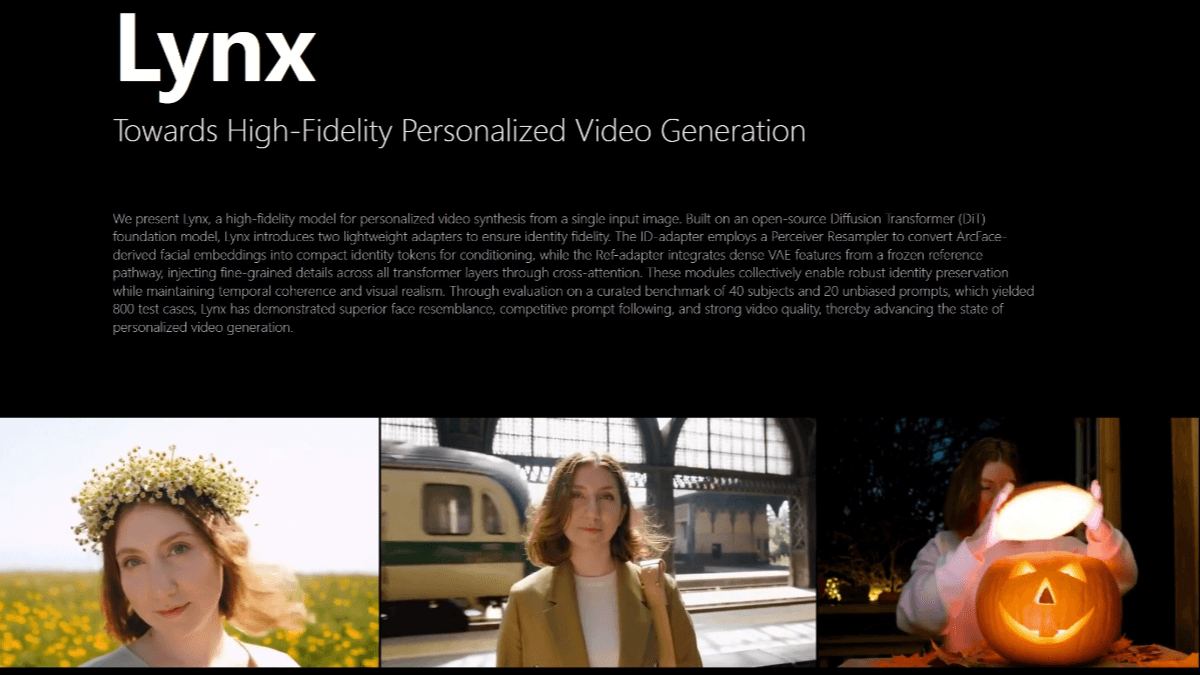
Lynx 是字节跳动开源的高保真个性化视频生成模型,仅需单张人像照片,能生成身份一致的视频。基于扩散 Transformer(DiT)基础模型构建,引入 ID-adapter 和 Ref-adapter 两个轻量级适配器模块,分别用于控制人物身份和保留面部细节。Lynx 采用人脸编码器捕捉面部特征,通过 X-Nemo 技术增强表情,LBM 算法模拟光影效果,确保人物身份在不同场景下的一致性。其交叉注意力适配器可将文本提示与人脸特征结合,生成符合场景要求的视频。Lynx 具备“时间感知器”,能理解动作物理规律,保持视频时间连贯性。在大规模测试中,Lynx 在面部相似度、场景匹配度和视频质量等多个维度上表现优异,超越同类技术。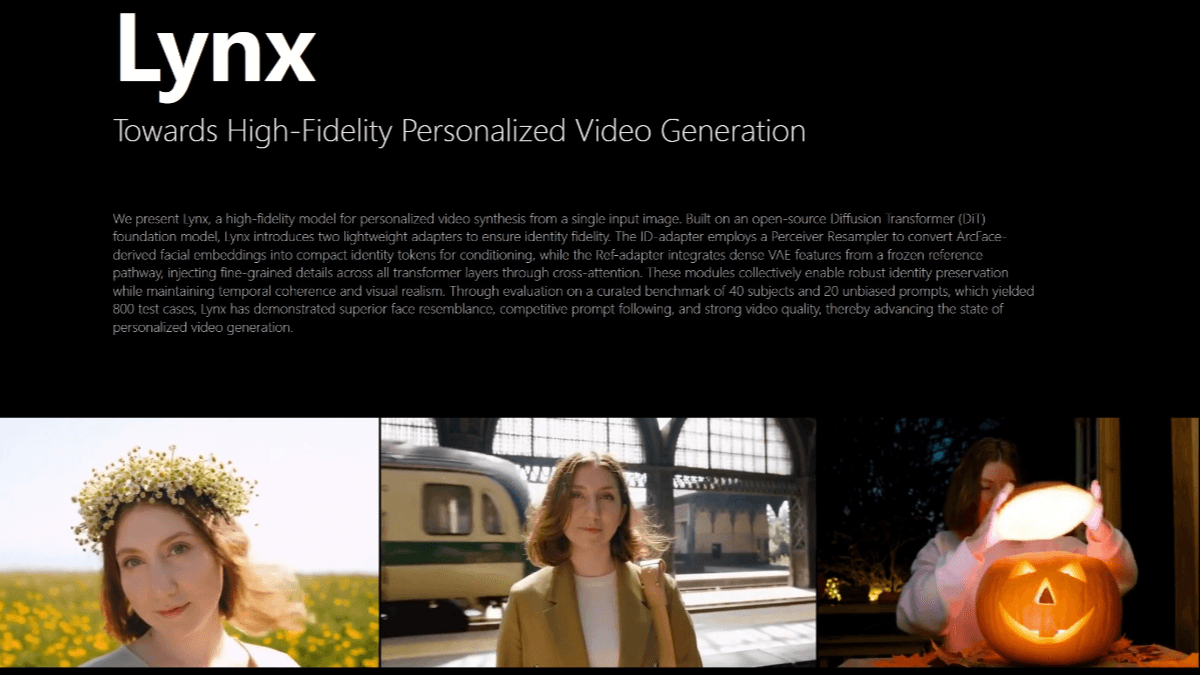
>>展开阅读