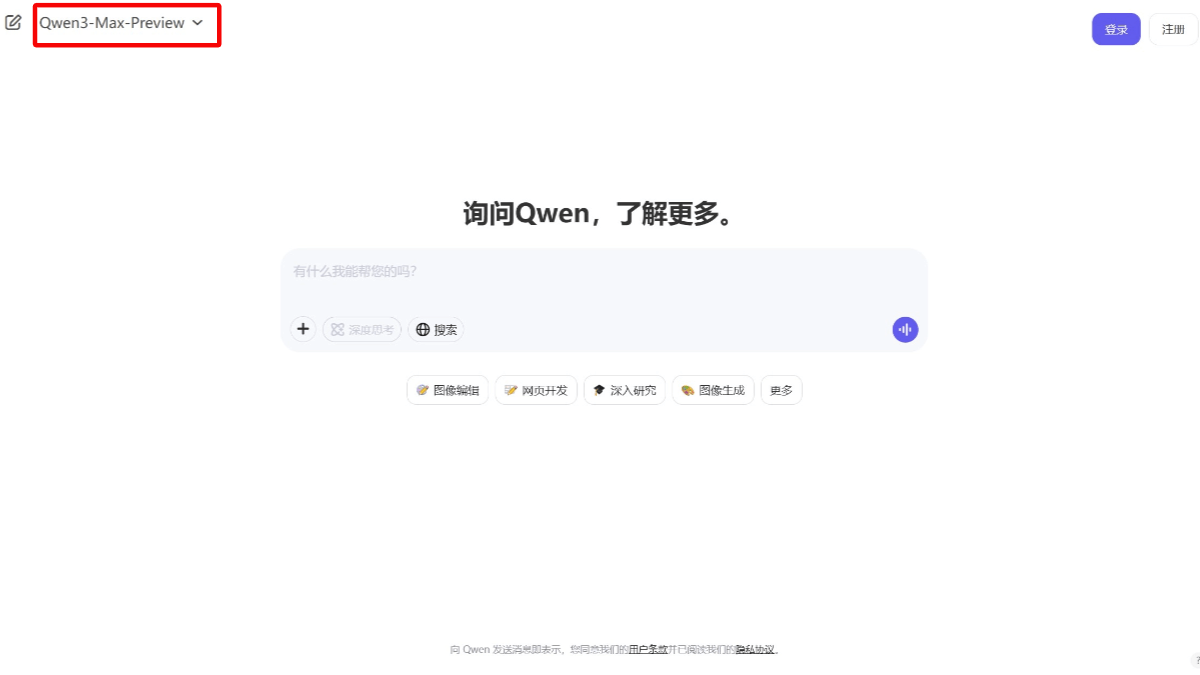
Qwen3-Max-Preview 是通义千问发布的最新旗舰大语言模型。是 Qwen3 系列中参数量最大的模型,参数规模超过 1 万亿。模型在推理、指令跟随、多语言支持和长尾知识覆盖等方面有重大改进,支持超过 100 种语言,中英文理解能力出色。在数学推理、编程和科学推理等任务中表现出色,能更可靠地遵循复杂指令,减少幻觉,生成更高质量的响应。用户可以通过 Qwen Chat 网页免费体验,也可以通过阿里云百炼平台的 API 进行调用。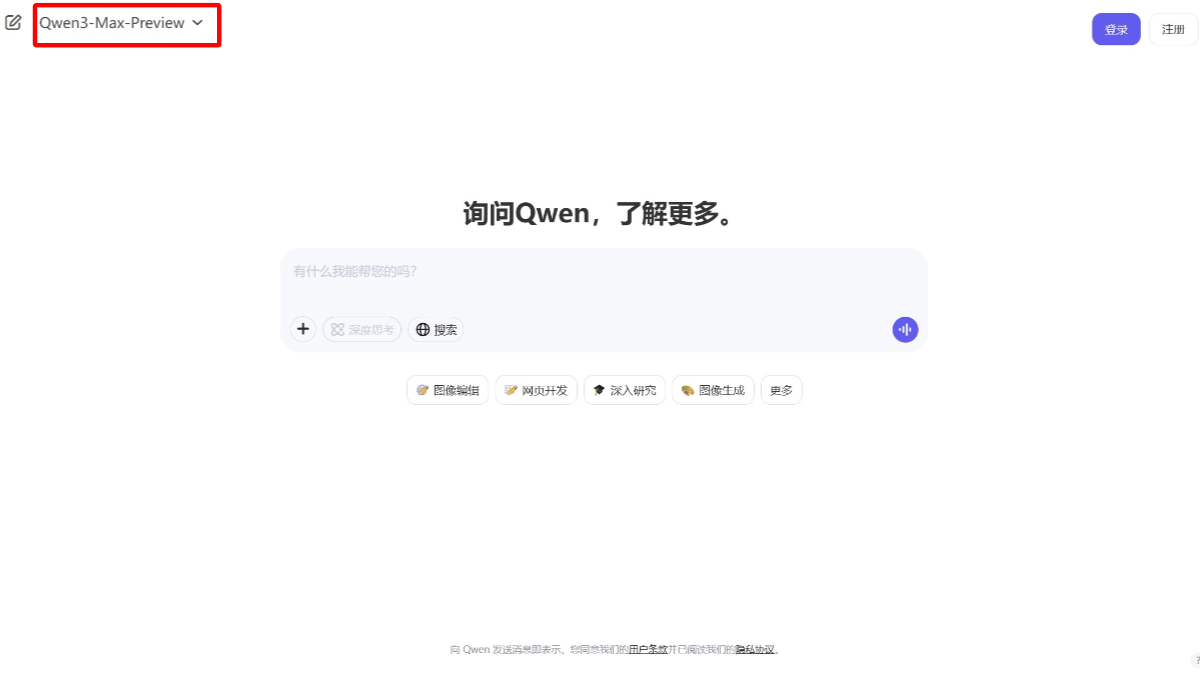
>>展开阅读
Seedream 4.0 是字节跳动推出的先进图像生成与编辑模型,以生成与编辑一体化为核心,具备精准指令编辑、高度特征保持、深度意图理解等强大功能。用户通过自然语言描述需求,能快速生成高质量图像,创意设计、广告制作和艺术创作,都能轻松应对。模型支持多图输入输出,能生成连贯图像序列,满足漫画、分镜等多帧创作需求。Seedream 4.0 支持生成超高清图像,确保细节清晰,为专业创作提供有力支持,是创作者的得力助手。访问豆包APP P图功能和即梦AI(模型内测中,部分用户可以使用)即可体验最新模型。
>>展开阅读
rStar2-Agent是微软开源的先进的人工智能数学推理模型,在AIME24测试中达到80.6%的准确率,展现出强大的数学问题解决能力。模型具备科学推理能力,在GPQA-Diamond基准测试中达到60.9%的准确率。模型通过智能体强化学习进行训练,具备高效工具调用能力,支持根据问题需求自动调用合适工具,如代码执行工具,提升问题解决效率。模型训练过程采用多阶段强化学习,结合GRPO-RoC算法,优化工具使用,大幅降低成本。
>>展开阅读
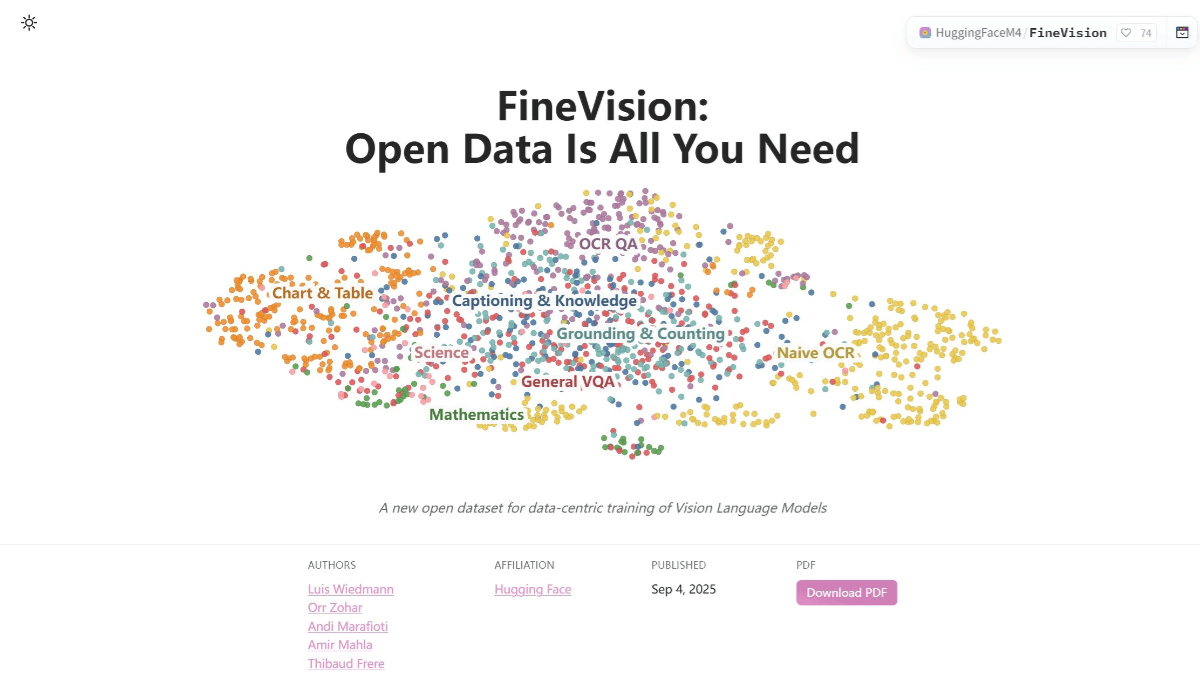
FineVision 是 Hugging Face 开源的视觉语言数据集,为训练先进的视觉语言模型。包含 1730 万张图像、2430 万个样本、8890 万轮对话和 95 亿个答案标记。数据集聚合了来自 200 多个来源的数据,具有多模态和多轮对话的特点,支持视觉和语言的结合。每张图像都配有文本标题,有助于模型理解和生成自然语言。FineVision 在 10 项基准测试中帮助模型平均提升了超过 20% 的性能。使用 Hugging Face 的 datasets 库可以轻松加载和使用数据集。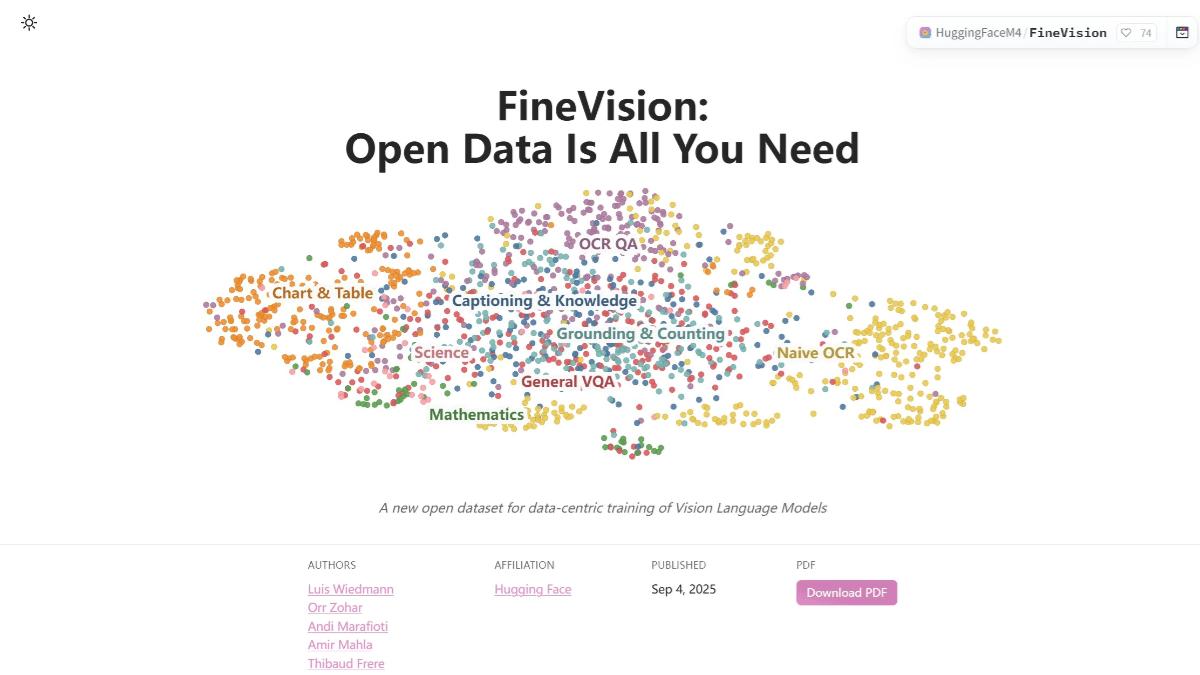
>>展开阅读
最近火爆全网的 AI 神器「Nano Banana」是谷歌推出的 Gemini 2.5 Flash Image 图像模型,可以生成超逼真手办人像,还支持场景换背景,修复老照片、转换艺术风格等等。
>>展开阅读
HunyuanWorld-Voyager(简称混元Voyager)是腾讯发布的业界首个支持原生3D重建的超长漫游世界模型。是一种新颖的视频扩散框架,能从单张图片生成用户定义相机路径的3D点云序列,支持沿着自定义相机轨迹进行世界探索的3D一致场景视频生成,可生成对齐的深度和RGB视频,用于高效直接的3D重建。模型包含两个关键组件:世界一致视频扩散和长距离世界探索,通过高效的点剔除和自回归推理实现迭代场景扩展。提出了一个可扩展的数据引擎,用于生成RGB-D视频训练的可扩展数据。
>>展开阅读
这期对话把火力对准了一个不体面的真相:更聪明的“路由”和更苛刻的“成本”正重写 AI 商业化的脚本。嘉宾阵容极具冲突感——半导体观察者 Dylan Patel,前谷歌云/企业家 Guido Appenzeller,风投人 Erin Price-Wright,与主持人 Erik Torenberg 一起,从 GPT-5 的“没加大算力却更会分配算力”谈起,直指 OpenAI 把免费用户与重度用户放在同一条计价胶带上滚动切割的现实逻辑。
>>展开阅读
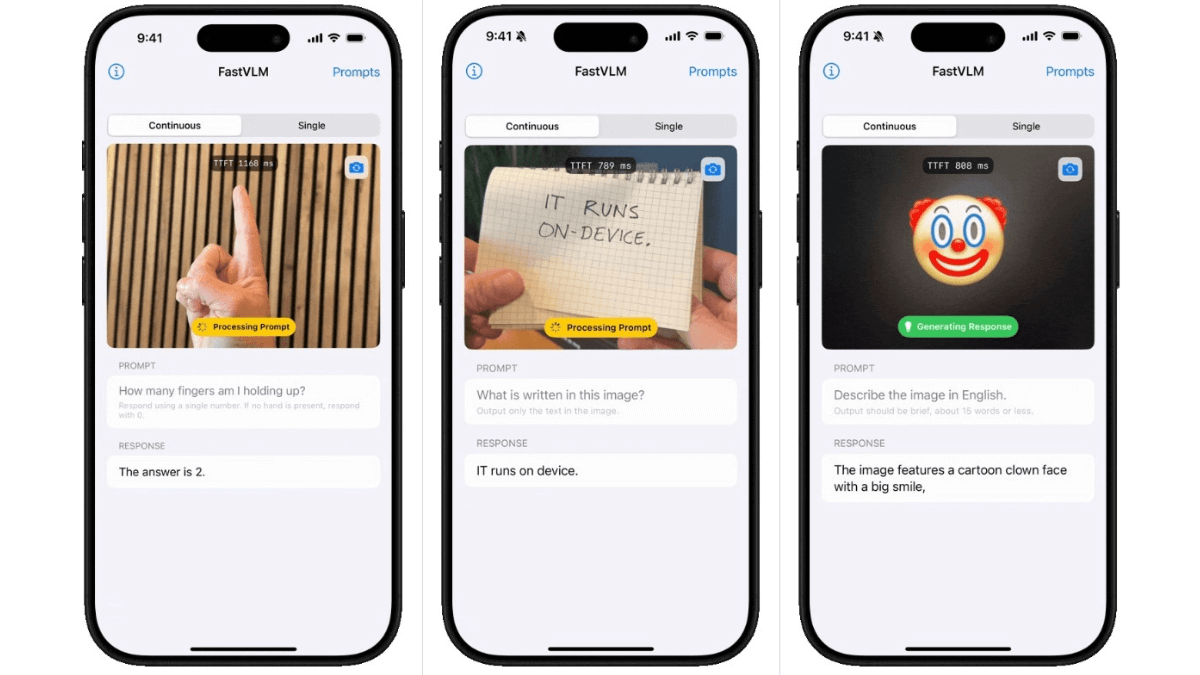
FastVLM(Fast Vision Language Model)是苹果公司推出的高效视觉语言模型。以FastViTHD混合视觉编码器为核心,融合了卷积和Transformer架构,可显著减少视觉token数量,降低编码时间和延迟。在处理高分辨率图像时,编码速度比同类模型快85倍,首次token生成时间(TTFT)提升了3.2倍,且视觉编码器尺寸更小,便于在移动设备上部署。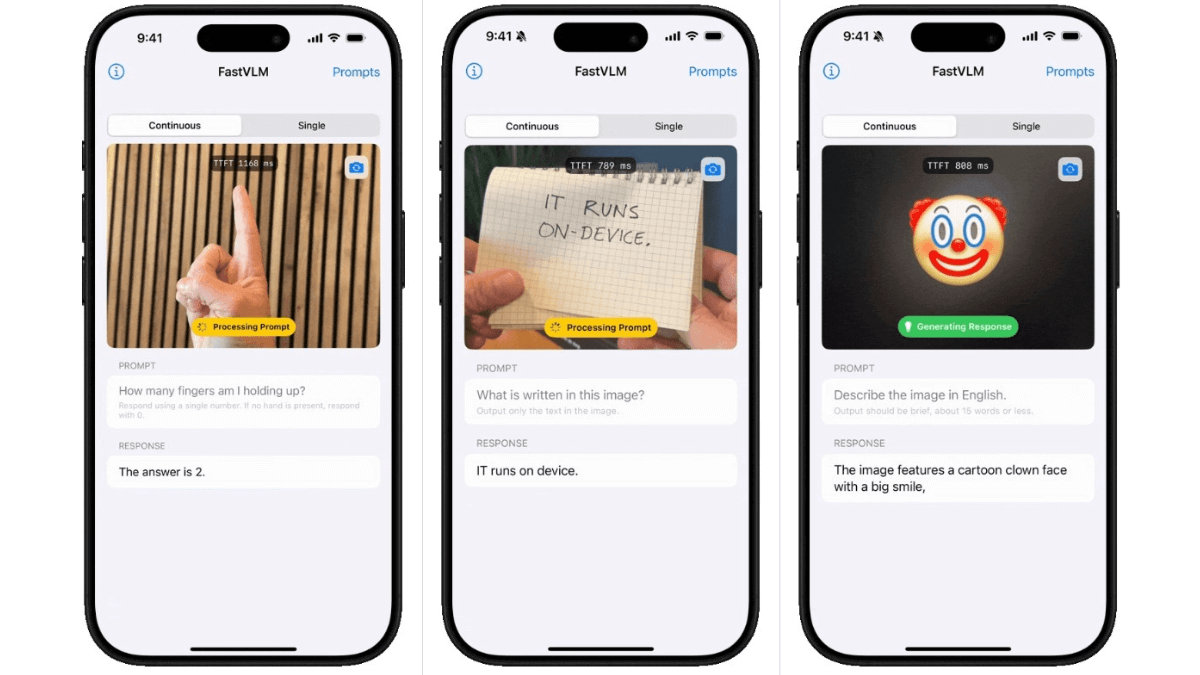
>>展开阅读
- «
- 1
- ...
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- ...
- 24
- »