FLUX.2是Black Forest Labs发布的开源图像生成与编辑模型,支持文生图、多图参考和图像编辑,具备更丰富的细节、清晰纹理和稳定光线。分为四个版本:FLUX.2 [pro](媲美顶级闭源模型)、FLUX.2 [flex](可调节参数)、FLUX.2 [dev](开源32B权重模型)和FLUX.2 [klein](即将推出的轻量化模型)。模型基于Mistral-3 24B视觉语言模型和Rectified Flow Transformer架构,能处理复杂排版、信息图和UI文字渲染,支持高达4MP分辨率的编辑。开源版本可在Hugging Face获取,商业授权需访问官网。
>>展开阅读
ViMax是香港大学数据科学实验室开源的多智能体视频生成框架,能实现从创意输入到视频输出的全流程自动化。整合了剧本生成、分镜设计、镜头规划和视频渲染等功能,支持用户通过自然语言描述生成连贯的影视级视频,特别擅长处理长篇小说转视频等复杂任务。框架采用MIT开源协议,提供本地部署方案,适用于自媒体、教育等内容创作场景。与传统AI视频工具相比,ViMax解决了角色不连贯、叙事结构缺失等问题,能自动生成带音画同步的完整视频。
>>展开阅读
一、Docker在机器学习场景中的核心价值
在传统机器学习开发中,环境配置是制约项目推进的首要难题。不同开发者的操作系统差异、Python版本冲突、依赖库版本不兼容等问题,常导致”在我机器上能运行”的经典困境。Docker通过容器化技术,将应用及其依赖环境打包为独立镜像,解决了这一核心痛点。
>>展开阅读
Pushing the frontiers of computer-use agents with an open-weight, ultra-compact model, optimized for real-world web tasks

>>展开阅读
HunyuanOCR是腾讯混元团队开源的高性能光学字符识别模型,参数量仅10亿。基于混元多模态架构开发,采用端到端设计,能高效处理文字检测、识别及文档解析任务。模型在复杂文档测试中得分94.1分,超越谷歌Gemini3-Pro等主流产品,支持14种小语种翻译。轻量化特性适用于票据识别、视频字幕提取等场景,开源地址为GitHub和Hugging Face平台。
>>展开阅读
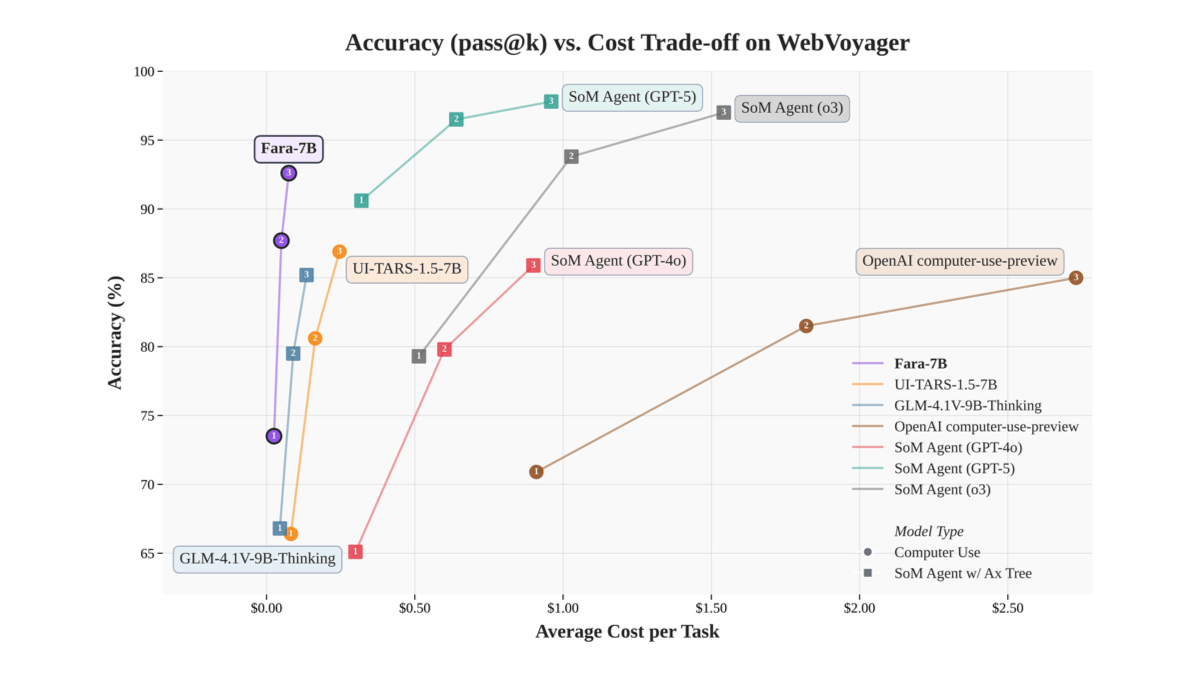
Fara-7B是微软开源发布的70亿参数规模的计算机操作代理(CUA)模型,基于Qwen2.5-VL-7B架构。通过视觉解析网页截图,在屏幕上执行点击、输入等操作,无需依赖额外的可访问性树或多个大模型协作,可直接在Windows 11本地运行,支持NPU加速,实现更低延迟和更好的隐私保护。Fara-7B在WebVoyager、Online-Mind2Web等公开基准测试中表现优异,任务成功率高,部分任务领先同级模型。采用全新的合成数据生成流程进行训练,包含大量任务轨迹和辅助任务数据,以监督微调为主。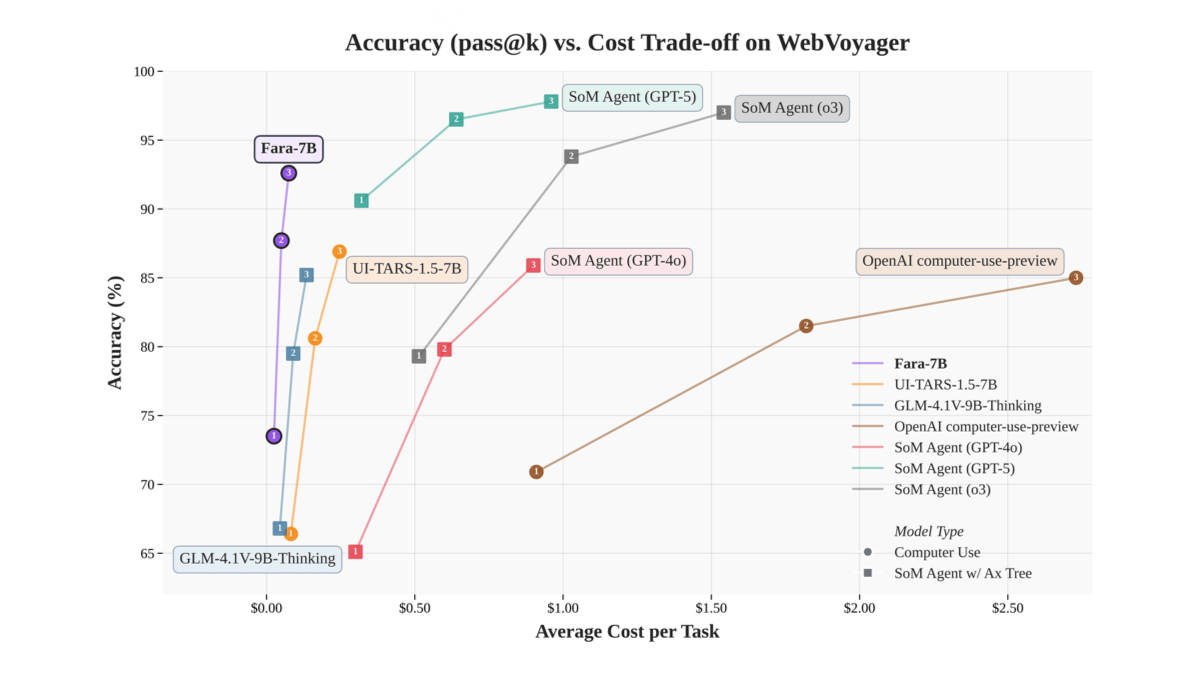
>>展开阅读
>>展开阅读
Supertonic是开源的高性能的文本转语音(TTS)系统,专注于在本地设备上快速生成语音。采用ONNX Runtime技术,可在手机、电脑甚至树莓派等设备上运行,支持23种语言和语音克隆,无需网络连接即可实现毫秒级响应。特色在于处理复杂文本的能力,能自然朗读包含数字、符号的非标准文本,适合开发实时语音应用。用户可通过GitHub获取开源代码和模型,支持Python、Node.js等多种编程环境。
>>展开阅读
- «
- 1
- 2
- 3
- 4
- 5
- 6
- ...
- 24
- »