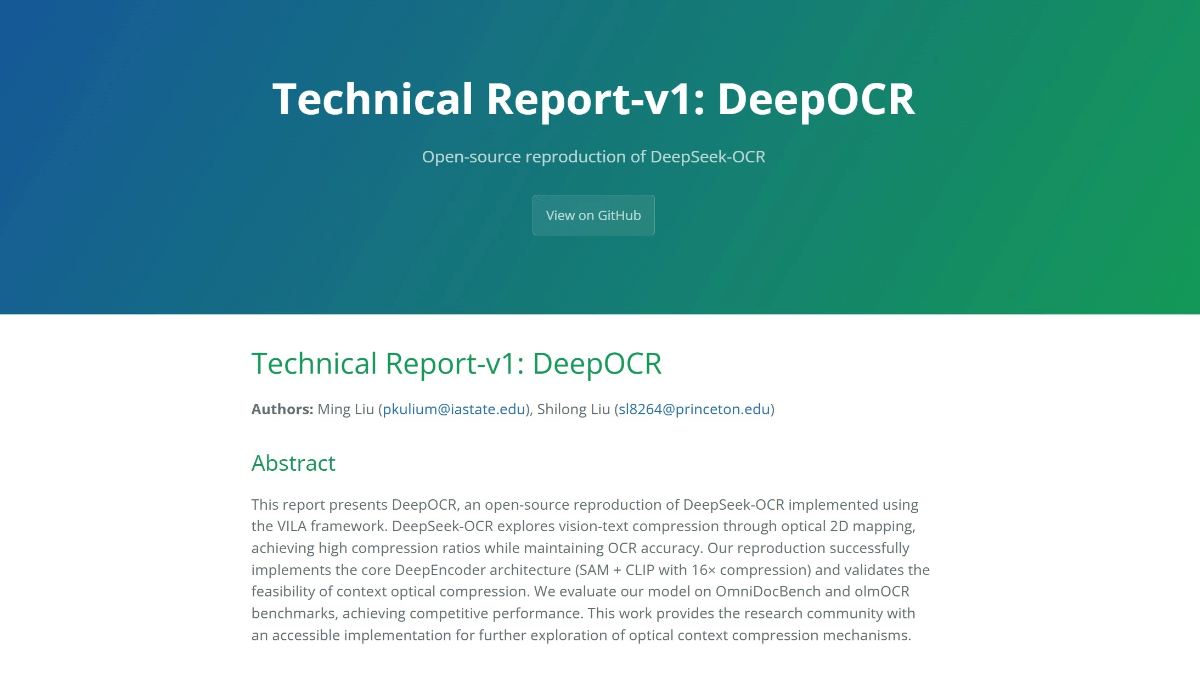
DeepOCR 是开源复刻项目,实现 DeepSeek-OCR 的核心架构,通过光学压缩技术高效处理文本信息。核心是 DeepEncoder,由 SAM-base(处理高分辨率图像)、16×卷积压缩器(减少 token 数量)和 CLIP-large(处理压缩后的特征)组成。这种设计在保持高分辨率处理能力的同时,显著降低了激活内存和 token 数量。DeepOCR 采用两阶段训练流程:第一阶段使用 LLaVA-CC3M 数据集进行视觉 - 语言对齐训练;第二阶段使用 olmOCR 数据集进行 OCR 特定预训练。通过这种训练方法,DeepOCR 在 OmniDocBench 和 olmOCR 基准测试中表现出色,尤其在英文文本识别和表格解析任务中,验证了光学压缩的有效性。
>>展开阅读
NocoBase是基于AI驱动的开源无代码开发平台,支持快速搭建业务系统,无需编程即可通过配置完成应用开发。项目采用Apache-2.0协议,提供私有化部署和灵活扩展能力,适用于企业管理、协作平台等场景。最新2.0版本已集成AI员工功能,可自动处理邮件分析、客户调研等任务,显著提升工作效率。
>>展开阅读
Handy是开源免费的本地语音转文字工具,支持Windows、MacOS和Linux系统,由Rust和React开发。通过本地处理语音数据,无需上传云端,保障隐私安全,适合快速转录和文字输入。用户可通过快捷键激活录音,支持多种语音模型(如Whisper),直接将转录结果粘贴到任意文本框。Handy特别适合需要隐私保护的办公或创作场景,安装包仅10MB,操作简单。
>>展开阅读
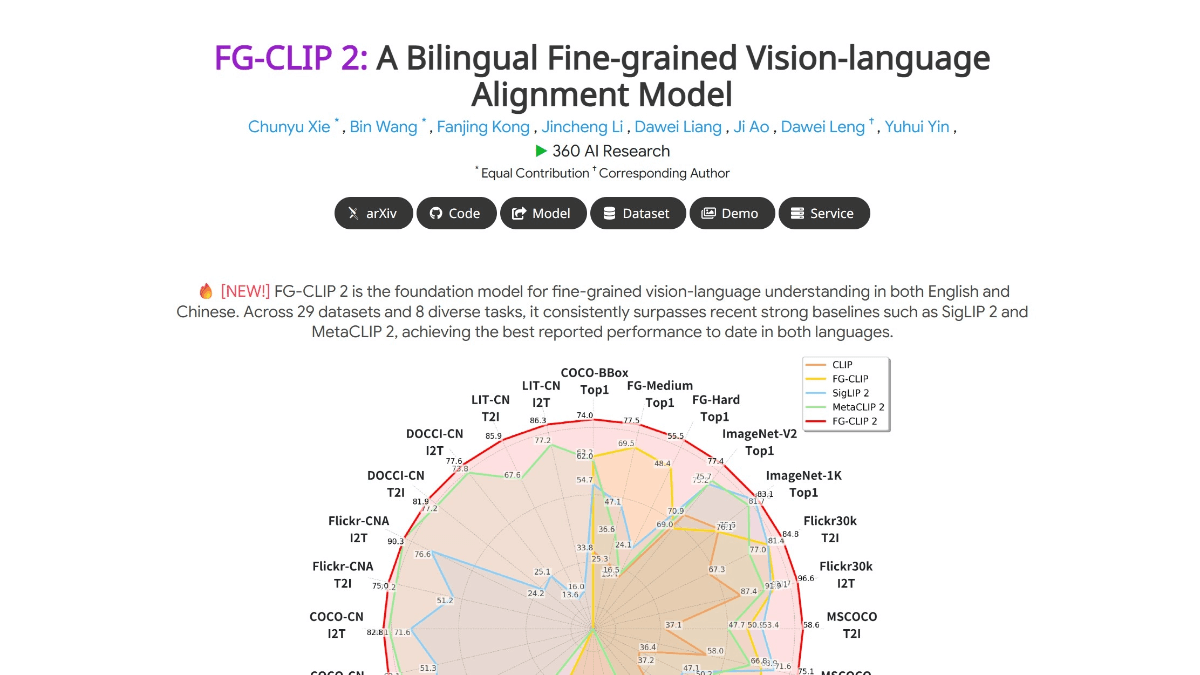
FG-CLIP 2 是360人工智能研究院推出的全球领先的图文跨模态视觉语言模型(VL-M),在29项权威基准测试中超越Google和Meta的同类模型,成为目前性能最强的VL-M。能精准识别图像中的毛发、斑点、色彩、表情、空间关系等细节,例如区分不同品种的猫、判断物体在屏幕内外的位置,甚至理解复杂场景中的遮挡关系。同时支持中文和英文的细粒度理解,填补了中文跨模态模型的空白,可精准处理中文长文本检索、区域分类等任务。采用两阶段训练策略,先全局对齐图文语义,再聚焦局部细节对齐;结合五维协同优化体系,提升模型的抗干扰性和鲁棒性。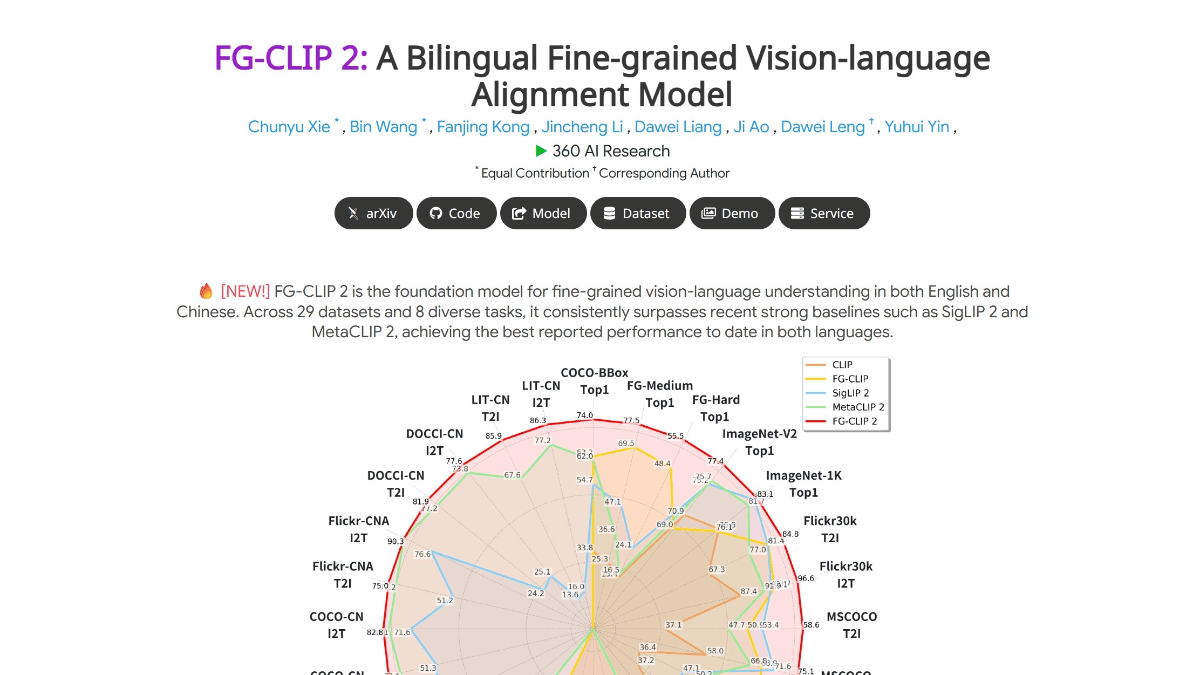
>>展开阅读
开源 AI 漫画翻译、图像翻译与编辑工具「Saber-Translator」支持多种模型、手动标注、精细编辑、会话管理和插件扩展!集成了从内容导入到编辑输出的完整工作流。提供多引擎、多语言 OCR 支持;多样化的 AI 翻译引擎。
>>展开阅读
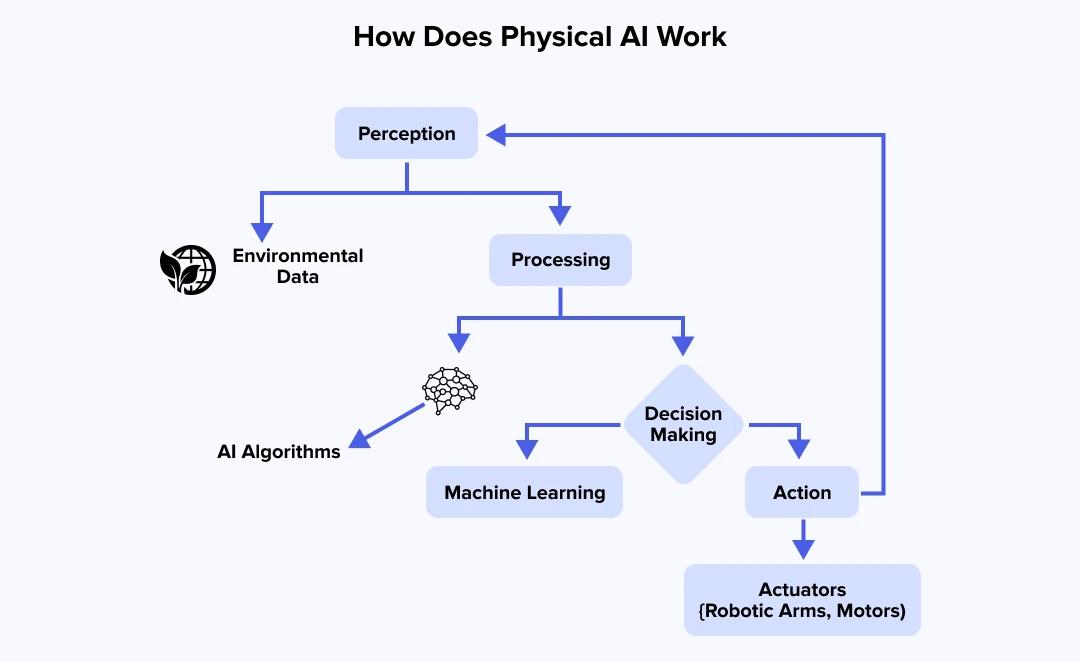
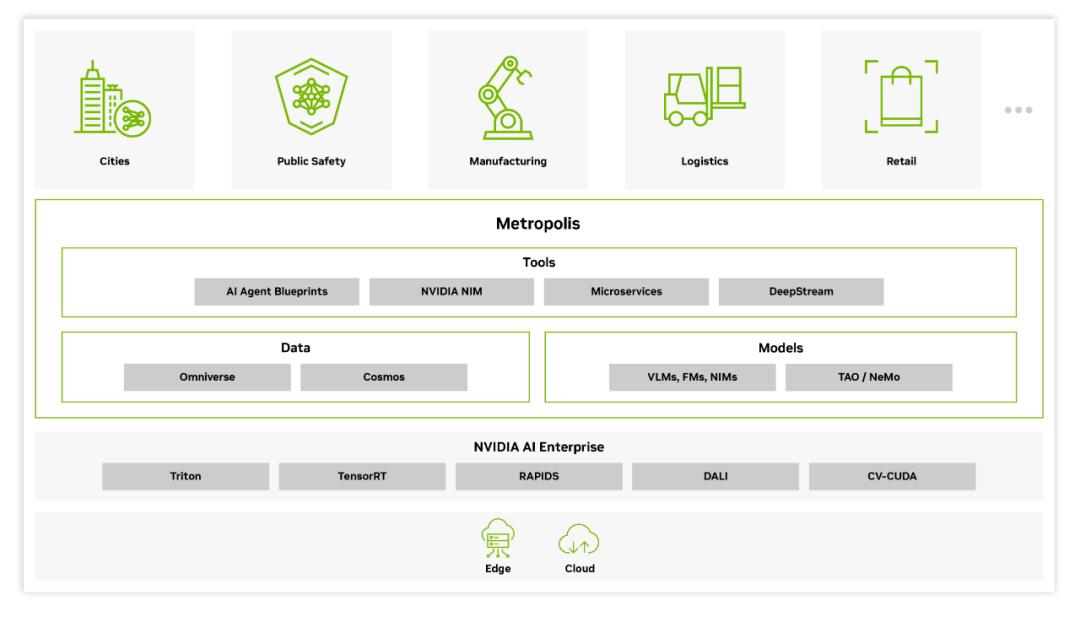

>>展开阅读
微舆(BettaFish)是开源的多智能体舆情分析系统。采用多智能体架构,通过Query、Media、Insight、Report等Agent协同工作,实现检索、抽取与报告闭环。系统支持AI驱动的全域监控,7×24小时不间断作业,覆盖微博、小红书、抖音等10多个国内外关键社媒。其复合分析引擎融合微调模型、统计模型等中间件与LLM协同工作,确保分析结果的深度、准度与多维视角。微舆具备强大的多模态能力,能深度解析短视频内容,精准提取结构化多模态信息卡片。系统提供高安全性的接口,支持将内部业务数据库与舆情数据无缝集成,打通数据壁垒。基于纯Python模块化设计,微舆实现轻量化、一键式部署,代码结构清晰,开发者可轻松集成自定义模型与业务逻辑。
>>展开阅读
Ouro是字节跳动Seed团队开发的新型循环语言模型(Looped Language Models),核心创新在于通过参数共享的循环计算结构,在预训练阶段直接构建推理能力。模型采用24层作为基础块,通过4次循环实现等效96层的计算深度,但保持1.4B参数规模,显著提升小模型的推理效率。实验显示,Ouro 1.4B在BBH推理基准上得分71.02,接近4B参数模型性能;2.6B版本在Math500数学题上达到90.85分,超越8B模型。其独特设计包括动态计算机制(简单任务少循环,复杂任务多循环)和熵正则化训练策略,使模型能自适应调整思考深度。
>>展开阅读
- «
- 1
- ...
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- ...
- 24
- »