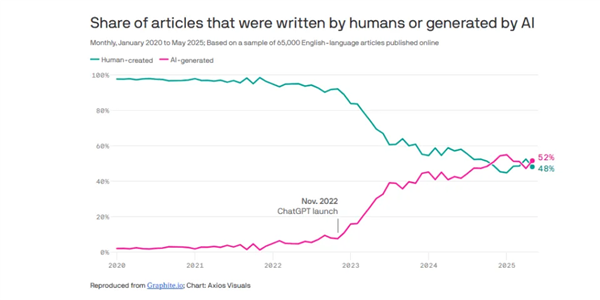
GigaBrain-0 - 开源的具身基础模型,由世界模型生成数据驱动
GigaBrain-0是国内首个利用世界模型生成数据实现真机泛化的端到端视觉-语言-动作(VLA)具身基础模型,由极佳视界与湖北人形机器人创新中心联合发布开源。采用混合Transformer架构,融合预训练视觉语言模型(VL-M)与动作扩散Transformer(DIT),支持RGB-D输入,增强3D空间感知能力。引入“具身思维链(Embodied CoT)”机制,生成中间推理步骤(如操作轨迹、子目标语言),提升长时程任务规划能力。以“世界模型”为核心构建数据引擎,通过仿真生成、风格迁移、视角变换等技术,生成多样化训练数据,减少对真实世界数据的依赖。数据覆盖工业、商业、办公、家居等多场景,提升模型泛化能力。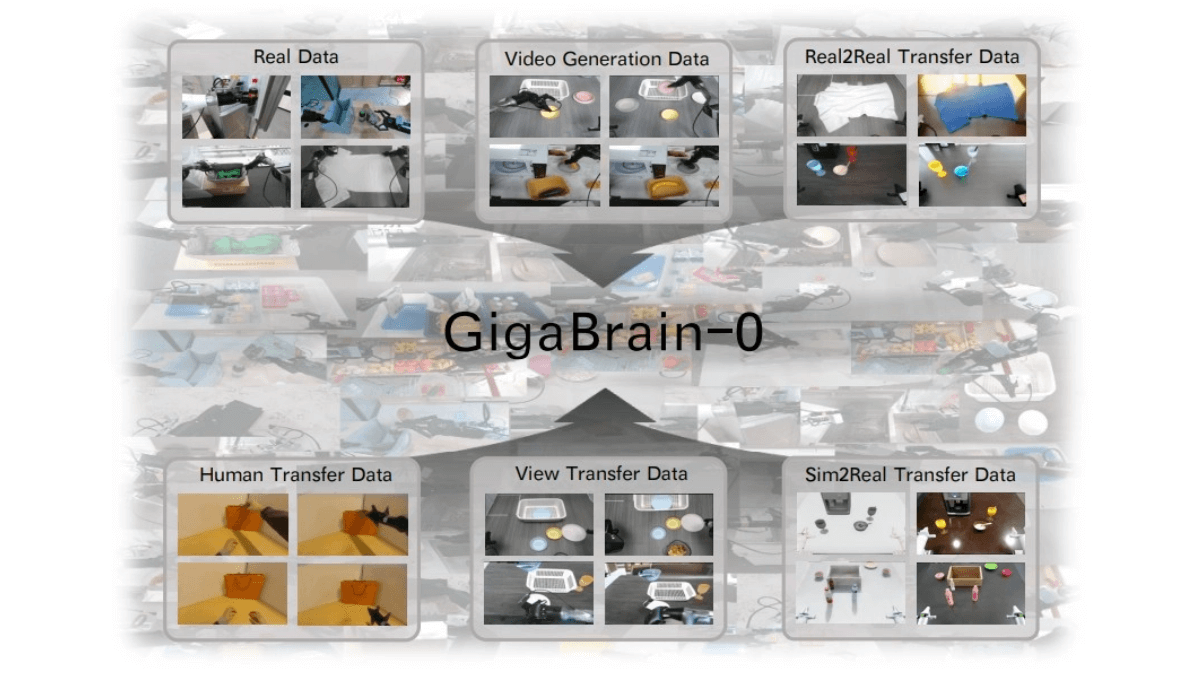
Ming-flash-omni-Preview - 蚂蚁集团开源的全模态大模型
Ming-flash-omni-Preview是蚂蚁集团inclusionAI发布的开源全模态大模型,参数规模达千亿,基于Ling 2.0的稀疏MoE架构,总参数103B,激活9B。在全模态理解和生成能力上表现出色,尤其在可控图像生成、流式视频理解、语音及方言识别、音色克隆等方面有显著优势。首创“生成式分割范式”,实现细粒度空间语义控制,图像生成可控性强;能对流式视频进行细粒度理解,实时提供说明;在语音领域,支持上下文感知语音理解及方言识别,对15种中国方言理解能力大幅提升,音色克隆能力也显著增强。模型的训练架构高效,通过多项优化提升了训练吞吐量。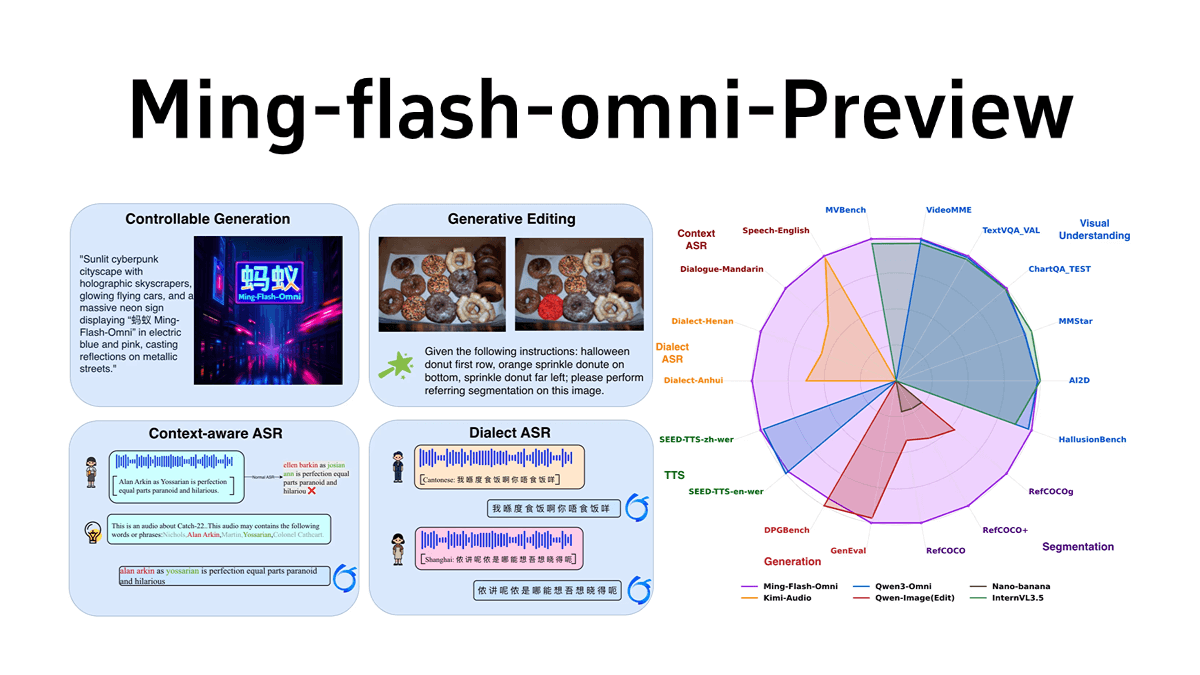
OmniVinci - NVIDIA开源的全模态大语言模型
OmniVinci 是 NVIDIA 开发的开源全模态大型语言模型,通过架构革新和数据优化解决多模态模型中的模态割裂问题。通过 OmniAlignNet 加强视觉和音频嵌入的对齐,利用时间嵌入分组捕捉相对时间对齐信息,采用约束旋转时间嵌入编码绝对时间信息。OmniVinci 通过数据合成和精心设计的数据分布策略,生成大量单模态和全模态对话样本进行训练。两阶段训练策略先进行单模态训练,再进行全模态联合训练,有效整合多模态理解能力。OmniVinci 在多个基准测试中表现优异,如在 DailyOmni 上评分比 Qwen2.5-Omni 高出 19.05 分,且训练标记量大幅减少。已应用于医疗 CT 影像解读、半导体器件检测等领域,展现出强大的多模态理解能力。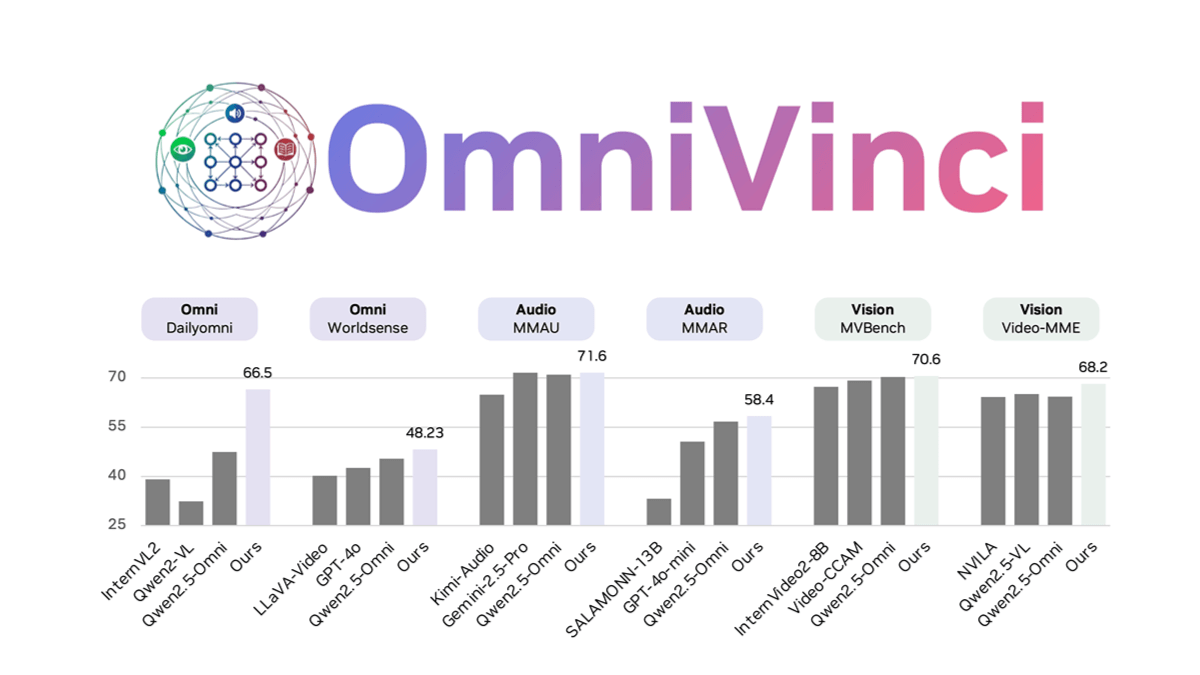
Dexbotic - 原力灵机开源的具身智能VLA模型一站式科研服务平台
Dexbotic是原力灵机(Dexmal)开源的具身智能视觉-语言-动作(VLA)模型一站式科研服务平台,解决具身智能领域研究碎片化、效率低等问题。以 PyTorch 为基础,为具身智能领域的研究和开发提供了一站式的解决方案。Dexbotic 的核心优势在于其统一的模块化框架,能兼容多种主流大语言模型接口,集成具身操作与导航模块,并预留了扩展能力,为未来更复杂的任务场景提供了架构基础。提供了高性能的预训练基础模型,针对多种主流算法进行了优化,显著提升了在仿真和真实任务中的表现。Dexbotic 支持云端和本地一体化训练,适配多种研发环境,提供了全链路的机器人训练与部署支持,覆盖从仿真验证到真实机器人落地的完整流程。
ValueCell - 开源的多智能体金融平台,多个Agent分工协作
ValueCell是开源的多智能体金融应用平台,通过AI技术提升金融分析和投资管理的效率。模拟专业投资团队,多个AI智能体分工协作,涵盖市场分析、情绪分析、基本面研究、自动交易等功能,为用户提供全面的金融洞察。支持OpenAI、OpenRouter等多种大语言模型,覆盖美股、A股、加密货币等多市场数据,兼容LangChain等主流AI框架。提供深度研究报告、自动交易策略、实时市场数据推送,以及基于知名投资大师理念的智能体(如巴菲特、芒格风格),帮助用户优化投资组合。
olmOCR 2 - AI2开源的多模态文档解析模型
olmOCR 2是Allen Institute for Artificial Intelligence(AI2)开源的多模态文档解析模型,是olmOCR的升级版本。将数字化的打印文档(如 PDF)高效转换为干净、自然排序的纯文本。基于Qwen2.5-VL-7B模型,通过强化学习(RLVR)优化,结合合成数据生成与单元测试机制,解决传统OCR在复杂场景(如数学公式、表格、多列布局)中的精度问题。在文档解析任务中表现突出,尤其在处理复杂格式和结构化内容时,准确率显著高于同类模型。例如,在数学公式识别、表格数据提取等任务中,能更精准地还原文档内容。
见证历史!互联网AI生成内容数量首超人类:52%比48%